RAG (Retrieval-Augmented Generation) là kiến trúc AI kết hợp tính năng truy xuất thông tin từ kho dữ liệu tin cậy bên ngoài với mô hình ngôn ngữ lớn (LLM) để tạo ra câu trả lời chính xác và cập nhật nhất. Đây được xem là nền tảng bắt buộc trong triển khai AI doanh nghiệp. Trong bối cảnh nhiều tổ chức đẩy mạnh ứng dụng mô hình của OpenAI để tự động hóa quy trình, rủi ro ảo giác (hallucination) vẫn là mối đe dọa đáng kể khi AI có thể tạo ra thông tin sai lệch, ảnh hưởng trực tiếp đến uy tín thương hiệu. RAG xuất hiện như một cơ chế kiểm soát quan trọng, bảo đảm AI chỉ phản hồi dựa trên dữ liệu đã được xác thực. Midas Agency sẽ phân tích cách RAG giúp website doanh nghiệp duy trì tính chính xác, minh bạch và an toàn trong mọi ứng dụng AI.
1. RAG là gì?
RAG là tên viết tắt của: Retrieval-Augmented Generation (Truy xuất – Bổ sung – Tạo sinh). Đây là một kiến trúc AI được thiết kế để tối ưu hóa đầu ra của các Mô hình ngôn ngữ lớn (LLM) bằng cách kết nối chúng với các nguồn dữ liệu tin cậy bên ngoài trước khi đưa ra câu trả lời.
Ví dụ: Để hình dung RAG là gì, hãy so sánh các AI truyền thống (như ChatGPT bản gốc) với một học sinh đi thi trắc nghiệm theo hình thức “Thi đóng” (Closed-book exam). Học sinh này chỉ dựa hoàn toàn vào trí nhớ từ quá trình học tập (huấn luyện) trước đó. Nếu câu hỏi liên quan đến một kiến thức mới phát sinh hoặc một chi tiết nhỏ mà học sinh đã quên, họ sẽ có xu hướng “đoán mò” và viết bậy để hoàn thành bài thi.
Ngược lại, RAG biến AI thành một học sinh tham gia “Thi mở” (Open-book exam). Học sinh này không cần học thuộc lòng mọi thứ. Thay vào đó, khi nhận được đề bài, học sinh (AI) sẽ được phép mang theo một chồng tài liệu nội bộ của công ty vào phòng thi. Nhiệm vụ của học sinh là mở đúng trang sách chứa thông tin, đọc kỹ đoạn văn đó, rồi mới đúc kết lại thành câu trả lời. Nhờ vậy, câu trả lời luôn đảm bảo tính xác thực và cập nhật.
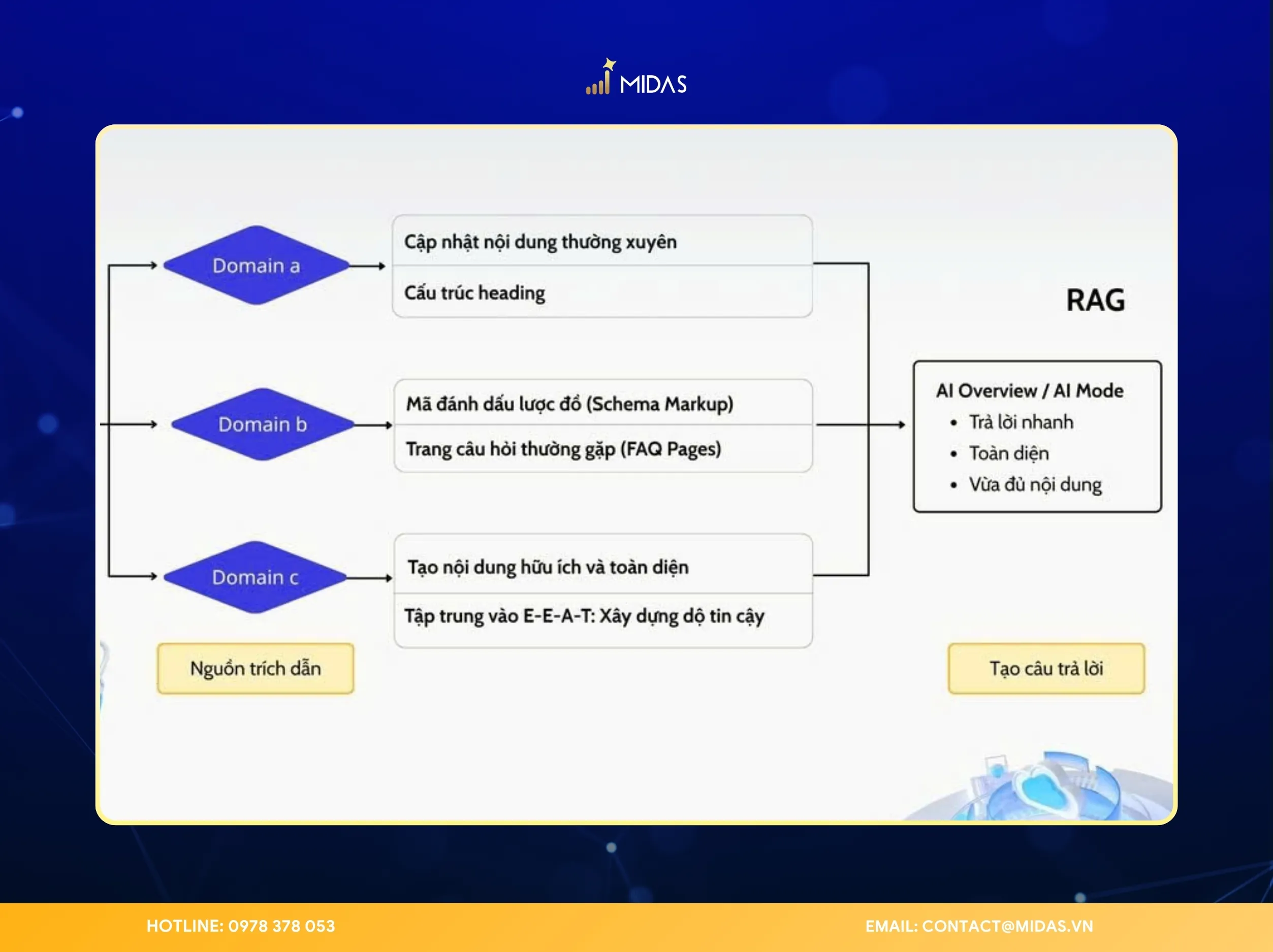
2. Hai thành phần cốt lõi của RAG
Một cấu trúc RAG tiêu chuẩn được vận hành bởi hai thực thể công nghệ tách biệt nhưng bổ trợ chặt chẽ:
- Hệ thống truy xuất (Retriever): Được ví như một “thủ thư kỹ thuật số” sử dụng công nghệ tìm kiếm ngữ nghĩa (Semantic Search). Thành phần này chịu trách nhiệm quét qua kho dữ liệu khổng lồ của doanh nghiệp (Vector Database) để trích xuất các đoạn thông tin có độ tương quan cao nhất với câu hỏi.
- Mô hình tạo sinh (Generator – LLM): Đóng vai trò là “người biên tập”. Sau khi nhận được các mảnh dữ liệu thô từ Retriever, Generator sẽ sử dụng khả năng ngôn ngữ tự nhiên để đúc kết thành một văn bản hoàn chỉnh, mạch lạc và đúng ngữ cảnh.
3. Lợi ích thiết yếu của RAG đối với doanh nghiệp
3.1. Tiết kiệm chi phí khổng lồ
Thay vì chi hàng triệu USD để xây dựng và huấn luyện một mô hình ngôn ngữ riêng (một quá trình tốn kém GPU và nhân sự chất lượng cao), RAG cho phép doanh nghiệp tận dụng sức mạnh của các LLM hàng đầu (như GPT-4) và chỉ cần đầu tư vào hệ thống lưu trữ dữ liệu Vector. Đây là giải pháp tối ưu hóa ngân sách nhưng vẫn đạt được hiệu suất chuyên gia.
3.2. Bảo mật dữ liệu tuyệt đối
Một trong những nỗi lo lớn nhất khi tiếp cận RAG là gì chính là an ninh thông tin. RAG cho phép doanh nghiệp kiểm soát chặt chẽ luồng dữ liệu. Dữ liệu nội bộ nhạy cảm có thể được lưu trữ tại máy chủ riêng (On-premise), AI chỉ truy cập để lấy thông tin tại thời điểm cần thiết mà không “học” và lưu giữ dữ liệu đó vào bộ não công cộng của nhà phát triển mô hình.
3.3. Cập nhật theo thời gian thực
Trong môi trường kinh doanh biến động, các quy định và giá cả thay đổi liên tục. RAG giúp hệ thống AI luôn ở trạng thái “cập nhật nhất”. Chỉ cần thay đổi một dòng trong file Excel quản lý giá, ngay lập tức Chatbot CSKH sẽ phản hồi mức giá mới cho khách hàng, loại bỏ hoàn toàn độ trễ về đào tạo.

Xem thêm: GEO là gì?
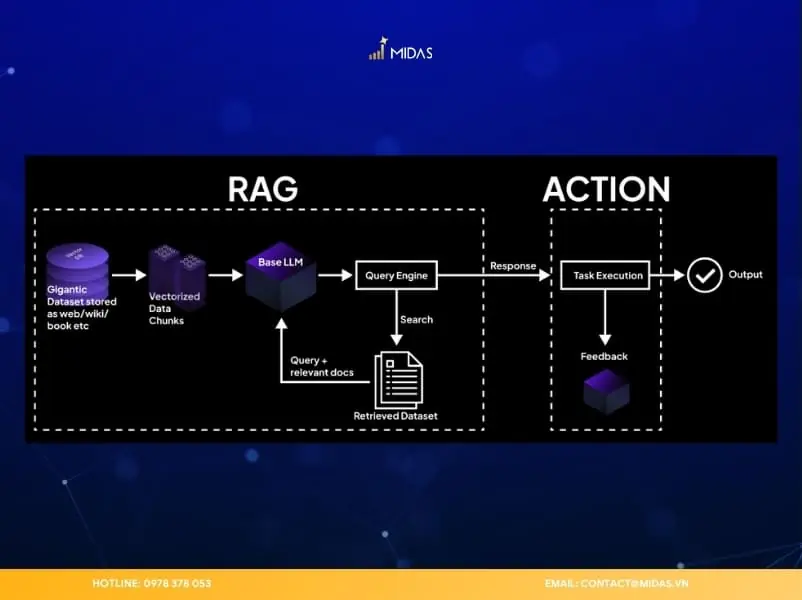
4. RAG hoạt động như thế nào?
Sức mạnh của RAG là gì nằm ở quy trình xử lý thông tin tuần tự và logic, giúp chuyển hóa dữ liệu thô thành tri thức có ích.
4.1. Giai đoạn Indexing (chuẩn bị dữ liệu)
Mục tiêu: Sắp xếp và chuyển đổi dữ liệu thành định dạng phù hợp để hệ thống có thể truy xuất thông tin nhanh và chính xác.
Quy trình indexing thường gồm ba bước quan trọng:
- Tách nội dung thành các phần nhỏ: Những tài liệu dung lượng lớn sẽ được cắt thành từng đoạn ngắn (thường 500–1000 tokens) để dễ quản lý và tăng độ chính xác khi truy vấn. Ví dụ: Một tài liệu 50 trang có thể được bóc tách thành khoảng 100 đoạn, mỗi đoạn mang một chủ đề hoặc nhóm thông tin riêng.
- Sinh vector embeddings: Văn bản được chuyển hóa thành các vector số, giúp mô hình hiểu được ý nghĩa thay vì chỉ nhận diện chữ. Ví dụ: Câu “React hooks giúp quản lý state” sẽ trở thành một vector gồm hàng nghìn giá trị như [0.12, -0.44, 0.91, …], thể hiện ngữ nghĩa của câu.
- Lưu trữ trong vector database: Những vector này được đưa vào các hệ quản trị cơ sở dữ liệu tối ưu cho tìm kiếm theo độ tương đồng. Ví dụ: Những lựa chọn phổ biến có thể kể đến như Pinecone, Milvus, Weaviate hoặc Chroma — nơi bạn có thể truy vấn các đoạn văn bản “tương tự về ý” thay vì chỉ dựa vào từ khóa.
4.2. Giai đoạn truy vấn (khi người dùng đặt câu hỏi)
Mã hóa câu hỏi thành vector: Khi có truy vấn, hệ thống sẽ chuyển câu hỏi của người dùng thành một vector số. Cách xử lý này tương tự như quá trình đã áp dụng cho dữ liệu trong bước indexing, giúp mô hình hiểu được ý nghĩa của câu hỏi.
Tìm kiếm theo ngữ nghĩa: Vector của câu hỏi được đối chiếu với các vector trong kho dữ liệu để xác định những đoạn văn bản có nội dung gần nhất về mặt ý nghĩa.
Ví dụ: Nếu người dùng hỏi “Cách xử lý concurrent requests như thế nào?”, hệ thống sẽ tự động tìm các đoạn liên quan đến “xử lý đồng thời”, “parallel processing” hoặc “async/await”, thay vì giới hạn trong vài từ khóa giống hệt.
Hình thành prompt mở rộng: Câu hỏi ban đầu được kết hợp với những đoạn nội dung đã truy xuất để tạo ra một prompt đầy đủ hơn. Mục đích là cung cấp cho mô hình ngôn ngữ (LLM) bối cảnh và thông tin chính xác để tạo câu trả lời chất lượng.
Ví dụ dữ liệu hỗ trợ:
- Node.js có Promise.all() để chạy nhiều promises song song.
- Kết hợp async/await với Promise.all giúp mã rõ ràng hơn.
- Với các tác vụ I/O-bound, event loop của Node.js có thể tự xử lý nhiều request.
Từ những phần thông tin này, hệ thống tổng hợp lại thành một prompt chi tiết.
LLM tạo ra câu trả lời: Dựa trên prompt mở rộng, LLM sẽ sinh ra phản hồi hoàn chỉnh, chính xác và phù hợp với ngữ cảnh của câu hỏi.
Xem thêm: SEO Google AI Overview
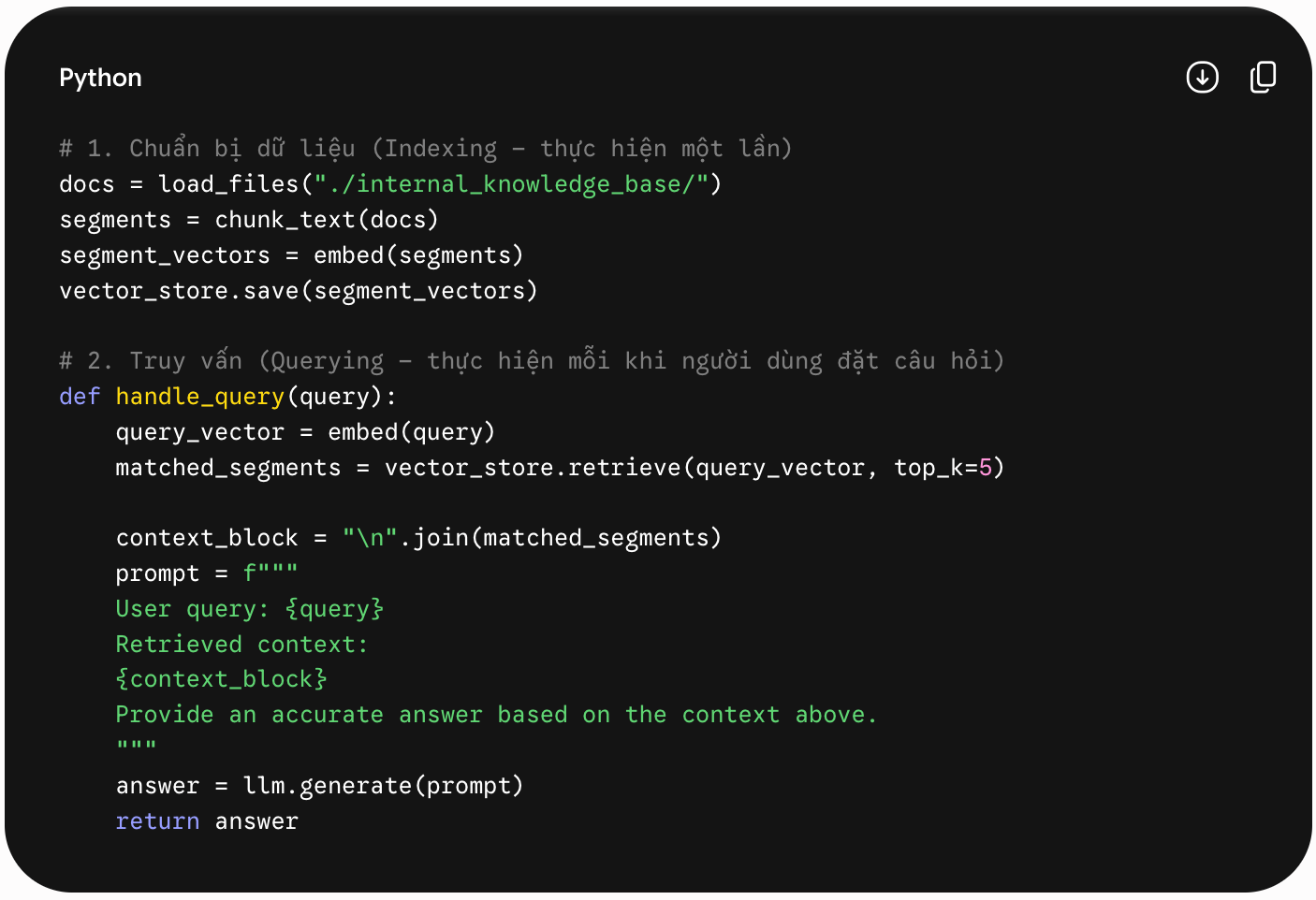
5. Ví dụ về cách triển khai RAG
6. Phân biệt RAG và Fine-tuning (Tinh chỉnh mô hình)
Khi tìm hiểu về RAG, nhiều người thường đặt nó cạnh Fine-tuning vì cả hai đều được sử dụng để nâng cao khả năng của mô hình ngôn ngữ lớn. Mục tiêu chung là cải thiện chất lượng phản hồi nhưng cách tiếp cận của chúng không giống nhau. Sự khác biệt này tạo ra những ứng dụng thực tiễn rất riêng cho từng phương pháp.
| Tiêu chí | RAG (Retrieval-Augmented Generation) | Fine-tuning |
| Phương thức hoạt động | Kết hợp mô hình ngôn ngữ với hệ thống truy vấn dữ liệu bên ngoài để tạo ra câu trả lời dựa trên thông tin được lấy về | Điều chỉnh mô hình bằng cách tiếp tục huấn luyện trên bộ dữ liệu bổ sung nhằm thay đổi hành vi hoặc kiến thức của mô hình |
| Khả năng cập nhật thông tin | Dễ dàng làm mới tri thức chỉ bằng cách thêm, sửa hoặc thay dữ liệu trong kho truy xuất | Việc cập nhật phức tạp hơn vì cần thực hiện lại quy trình huấn luyện khi có thông tin mới |
| Chi phí vận hành | Tối ưu chi phí do không cần tái huấn luyện toàn bộ mô hình | Chi phí cao hơn vì đòi hỏi tài nguyên tính toán và thời gian để huấn luyện lại |
| Mức độ mở rộng | Linh hoạt, có thể kết nối với nhiều nguồn dữ liệu khác nhau | Hạn chế bởi bộ dữ liệu dùng để fine-tune và khó mở rộng khi cần thêm nguồn mới |
| Độ tin cậy và khả năng giải thích | Kết quả có thể kiểm chứng vì thông tin được truy xuất từ nguồn cụ thể | Phụ thuộc hoàn toàn vào dữ liệu huấn luyện, khó xác định chính xác nguồn gốc thông tin mà mô hình sinh ra |

7. Ứng dụng thực tế của RAG trong Marketing & Vận hành
Sức mạnh thực sự của RAG không nằm ở lý thuyết, mà ở khả năng giải quyết các bài toán hóc búa về dữ liệu trong thế giới thực. Dưới đây là 5 kịch bản ứng dụng điển hình giúp doanh nghiệp tối ưu hóa hiệu suất và trải nghiệm khách hàng.
Chatbot hỗ trợ khách hàng (CSKH)
RAG giúp chatbot truy xuất trực tiếp dữ liệu tồn kho, giá bán, chính sách bảo hành hoặc điều kiện đổi trả từ hệ thống nội bộ. Nhờ đó, khách hàng nhận được câu trả lời đúng theo dữ liệu doanh nghiệp đang áp dụng, thay vì các phản hồi chung chung hoặc suy đoán. Điều này đặc biệt quan trọng với ngành bán lẻ và thương mại điện tử, nơi sai lệch thông tin có thể gây khiếu nại, hoàn hàng hoặc ảnh hưởng uy tín thương hiệu.
Công cụ hỗ trợ nhân viên (HR/Admin Bot)
Với RAG, AI có thể hướng dẫn nhân viên mới tra cứu chính xác quy trình xin nghỉ phép, đăng ký cấp laptop, quy định công tác phí hoặc các chính sách nội bộ. Thay vì làm gián đoạn HR liên tục, nhân viên có thể tự tìm câu trả lời dựa trên kho dữ liệu đã được chuẩn hóa. Điều này giúp giảm tải chi phí vận hành và tăng tốc độ xử lý công việc hằng ngày.
Tìm kiếm tri thức nội bộ (Knowledge Management)
RAG biến toàn bộ lịch sử tài liệu, báo cáo, SOP, tài liệu đào tạo và email quan trọng của doanh nghiệp thành một thư viện tri thức có thể trò chuyện được. Nhân viên chỉ cần đặt câu hỏi và nhận câu trả lời dựa trên dữ liệu thật, thay vì mất hàng giờ dò tìm trong các thư mục cũ. Đây là yếu tố cốt lõi trong việc bảo tồn tri thức tổ chức và hạn chế rủi ro “mất kiến thức” khi nhân sự nghỉ việc.
Hỗ trợ y tế
Trong lĩnh vực y tế, độ chính xác là yếu tố sống còn. RAG cho phép bác sĩ hỏi AI về hướng dẫn điều trị theo phác đồ chính thức và nhận câu trả lời trích xuất từ tài liệu hiện hành. Nhờ đó, AI không tự suy đoán hoặc đưa ra lời khuyên không chuẩn y khoa, giúp giảm thiểu sai sót và hỗ trợ bác sĩ trong tra cứu nhanh.
Hỗ trợ về tài chính – luật
RAG có khả năng đọc và phân tích khối lượng hợp đồng hoặc văn bản pháp lý lớn, sau đó trích xuất đúng điều khoản quan trọng như ràng buộc cạnh tranh, trách nhiệm pháp lý hay thời hạn hợp đồng. Điều này giúp đội ngũ pháp chế và tài chính tiết kiệm thời gian, đồng thời giảm nguy cơ bỏ sót chi tiết quan trọng.

Lưu ý quan trọng từ Midas Agency: Mặc dù RAG giúp tăng độ chính xác lên mức tối đa bằng cách bám sát dữ liệu nguồn, nhưng đối với các lĩnh vực đòi hỏi tính pháp lý hoặc đạo đức cao (Y tế, Luật pháp, Tài chính), hệ thống chỉ nên đóng vai trò là “Trợ lý hỗ trợ ra quyết định”. Mọi phản hồi từ AI vẫn cần được các chuyên gia/nhân sự có chuyên môn kiểm duyệt (Quality Control) trước khi đưa ra quyết định cuối cùng hoặc áp dụng cho khách hàng. Công nghệ là công cụ, nhưng tư duy và trách nhiệm của con người mới là yếu tố quyết định sự chuẩn xác tuyệt đối.
8. Những “điểm mù” kỹ thuật trong triển khai RAG
Dù là một giải pháp đột phá, việc triển khai RAG không phải luôn trải đầy hoa hồng. Doanh nghiệp cần nhìn nhận khách quan các thách thức kỹ thuật sau:
Chất lượng dữ liệu (Garbage in, Garbage out)
Đây là rào cản lớn nhất. AI chỉ là bộ máy xử lý; nếu dữ liệu doanh nghiệp cung cấp bị mâu thuẫn (ví dụ: file chính sách cũ chưa xóa, file mới đã nạp), RAG có thể truy xuất nhầm thông tin lỗi thời. Việc làm sạch và cấu trúc hóa dữ liệu (Data Cleaning) là điều kiện tiên quyết.
Giải pháp: Việc làm sạch và cấu trúc hóa dữ liệu (Data Cleaning & Structuring) là điều kiện tiên quyết. Tại Midas Agency, chúng tôi áp dụng quy trình chuẩn hóa dữ liệu đầu vào, đảm bảo thông tin được phân loại, gán nhãn và làm sạch trước khi đưa vào hệ thống vector hóa.
Độ trễ hệ thống (Latency)
Quy trình của RAG bao gồm thêm bước “truy xuất ngữ nghĩa” (Semantic Search) trước khi tạo câu trả lời. Điều này khiến tốc độ phản hồi chậm hơn từ 1-2 giây so với việc chat trực tiếp với LLM thông thường. Đối với các ứng dụng cần tốc độ cực nhanh, đây là một bài toán cần tối ưu hóa hạ tầng.
Giải pháp: Sử dụng các kỹ thuật tiên tiến như Caching (lưu trữ kết quả các truy vấn thường gặp) và Re-ranking (đánh giá lại độ liên quan của các kết quả trả về). Các chuyên gia của Midas sẽ tối ưu hóa hạ tầng và thuật toán để đảm bảo phản hồi của AI luôn mượt mà trong tích tắc.
Chi phí vận hành Vector Database
Việc duy trì và cập nhật cơ sở dữ liệu Vector đòi hỏi chi phí định kỳ và đội ngũ kỹ thuật am hiểu về kiến trúc dữ liệu AI để đảm bảo hệ thống luôn hoạt động chính xác.
Giải pháp: Xây dựng lộ trình triển khai tinh gọn ngay từ đầu. Chúng tôi giúp bạn chọn lọc các công cụ và cơ sở dữ liệu vector phù hợp với quy mô thực tế, giúp tối ưu hóa chi phí từ hạ tầng đến nhân sự vận hành.
Lời khuyên từ chuyên gia Midas Agency: Những thách thức nêu trên là hoàn toàn có thật, nhưng chúng không phải là “ngõ cụt”. Sự khác biệt giữa một dự án AI thành công và một hệ thống lỗi thời nằm ở chiến lược triển khai (RAG-Ops). Thay vì tự loay hoay, hãy xây dựng lộ trình chuẩn hóa ngay từ khâu xử lý dữ liệu đầu vào đến việc tinh chỉnh công cụ tìm kiếm. Việc đầu tư đúng kỹ thuật ngay từ đầu chính là cách tốt nhất để tiết kiệm hàng ngàn giờ khắc phục sự cố và chi phí vận hành sai lệch sau này.
9. Doanh nghiệp nên ứng dụng RAG theo cách nào?
Để khai thác hiệu quả RAG, doanh nghiệp cần một lộ trình rõ ràng. Cách tiếp cận vừa phải dễ triển khai giai đoạn đầu, vừa đảm bảo tính bền vững khi vận hành lâu dài. Các bước quan trọng gồm:
9.1. Lựa chọn bài toán ưu tiên
Khởi đầu từ những tình huống đòi hỏi độ chính xác cao và khả năng cập nhật tức thời. Những lĩnh vực như chăm sóc khách hàng, tư vấn pháp lý hoặc truy vấn tài liệu kỹ thuật thường là lựa chọn phù hợp.
9.2. Chuẩn hóa dữ liệu nội bộ
Tổng hợp và tổ chức lại các tài liệu quan trọng. Các tài liệu như quy định, hướng dẫn, bộ câu hỏi thường gặp hoặc tài liệu chuyên môn cần được làm sạch và định dạng thống nhất. Điều này giúp hệ thống truy xuất thông tin mượt mà và đúng trọng tâm.
9.3. Xây dựng hạ tầng RAG
Thiết lập cơ sở dữ liệu vector để phục vụ tìm kiếm theo ngữ nghĩa và kết hợp với mô hình ngôn ngữ lớn để tạo câu trả lời. Doanh nghiệp cũng cần thiết kế quy trình xử lý từ bước truy xuất đến bước tạo đầu ra sao cho liền mạch và ổn định.
9.4. Đảm bảo an toàn dữ liệu toàn bộ hệ thống
Triển khai bảo mật ở mọi giai đoạn như phân quyền người dùng, mã hóa thông tin và theo dõi các hoạt động truy cập. Đây là yếu tố quan trọng nhằm tránh rủi ro lộ lọt dữ liệu.
9.5. Phát triển đội ngũ MLOps và duy trì vận hành
Xây dựng nhóm phụ trách theo dõi chất lượng phản hồi và cập nhật nguồn dữ liệu khi cần. Việc tối ưu quy trình thường xuyên giúp hệ thống RAG luôn hoạt động hiệu quả và phù hợp với nhu cầu doanh nghiệp theo thời gian.
9.6. Thử nghiệm nhỏ trước khi mở rộng
Bắt đầu bằng một nhóm nghiệp vụ hoặc một bộ phận cụ thể để đánh giá hiệu quả thực tế. Khi mô hình đã ổn định và quy trình được tối ưu, doanh nghiệp có thể mở rộng triển khai sang toàn tổ chức.
10. Xu hướng và tương lai của RAG
Trong bối cảnh AI ngày càng trở thành một phần quan trọng trong hoạt động doanh nghiệp, RAG được xem là công nghệ chủ chốt giúp khai thác kho tri thức nội bộ một cách thông minh. Không chỉ cải thiện độ chính xác trong quá trình tạo câu trả lời, RAG còn cho phép kết hợp linh hoạt với nhiều giải pháp công nghệ khác, từ đó tối ưu hiệu suất vận hành. Một số xu hướng đáng chú ý gồm:
- Ứng dụng mở rộng tại APAC và trên toàn cầu: Những tên tuổi lớn như Microsoft, Google và Nvidia đang chủ động đưa RAG vào hệ sinh thái sản phẩm của mình. Điều này thúc đẩy sự lan rộng của công nghệ RAG trên thế giới, đặc biệt là tại khu vực châu Á – Thái Bình Dương.
- Kết hợp với Edge AI: Việc đồng bộ khả năng xử lý cục bộ của Edge AI với cơ chế truy vấn – tổng hợp thông tin của RAG giúp doanh nghiệp có thể phản hồi nhanh hơn, đồng thời duy trì mức độ bảo mật dữ liệu cao.
- Sự bùng nổ của cơ sở dữ liệu vector: Dự báo thị trường vector database sẽ đạt khoảng 4,3 tỷ USD vào năm 2028, trở thành cấu phần quan trọng của hệ thống RAG nhờ hỗ trợ tìm kiếm ngữ nghĩa và xử lý hiệu quả các dữ liệu phi cấu trúc.

11. Kết luận
Nhìn lại toàn cảnh, RAG là gì? Nó chính là cầu nối chiến lược mang sức mạnh trí tuệ nhân tạo toàn cầu áp dụng trực tiếp vào kho dữ liệu tư hữu (Private data) của doanh nghiệp một cách an toàn, minh bạch và chính xác nhất. RAG giúp doanh nghiệp thoát khỏi nỗi lo về “ảo giác AI” và biến trí tuệ nhân tạo thành một trợ lý chuyên gia thực thụ.
Tuy nhiên, để thương hiệu của bạn không chỉ “thông minh” ở bên trong mà còn phải trở thành “nguồn tin cậy ưu tiên” trong các cuộc hội thoại của AI Search (ChatGPT, Gemini, Perplexity), bạn cần một chiến lược SEO AI (GEO – Generative Engine Optimization) bài bản. Nếu không được tối ưu để trở thành một “thực thể uy tín” (Entity Authority), thương hiệu của bạn sẽ mãi là ẩn số trước sức mạnh của AI.
Tại Midas Agency, chúng tôi giúp bạn kết hợp hoàn hảo giữa sức mạnh nội tại từ RAG và chiến lược hiển thị đột phá từ SEO AI.
TÌM HIỂU LỘ TRÌNH CHIẾN LƯỢC SEO AI/GEO TOÀN DIỆN TẠI ĐÂY
Hãy để Midas Agency đồng hành cùng bạn xây dựng nền tảng AI an toàn, hiệu quả và chiếm lĩnh vị thế dẫn đầu trong kỷ nguyên trí tuệ nhân tạo ngay hôm nay.
🌐 Website: https://midas.vn/
☎️ 0978 378 053
📩 contact@midas.vn
🏢 158 Đường số 2, Khu đô thị Vạn Phúc City, Phường Hiệp Bình Phước, Thủ Đức, Thành phố Hồ Chí Minh
12. Câu hỏi thường gặp (FAQs)
Doanh nghiệp nhỏ (SME) có đủ ngân sách làm RAG không?
Hoàn toàn có thể. Hiện nay có rất nhiều nền tảng RAG mã nguồn mở (như LangChain, LlamaIndex) và các dịch vụ đám mây trả phí theo dung lượng (Pay-as-you-go). SME có thể bắt đầu với quy mô nhỏ, tập trung vào một bộ phận (như CSKH) với chi phí chỉ vài trăm USD mỗi tháng thay vì phải đầu tư hàng tỷ đồng cho hạ tầng riêng.
Dữ liệu đưa vào hệ thống RAG có bị lộ ra ngoài internet không?
Không, nếu bạn chọn đúng giải pháp. Doanh nghiệp có thể triển khai Private RAG trên các máy chủ đám mây riêng tư (AWS, Azure, Google Cloud với chế độ bảo mật cao) hoặc chạy các mô hình ngôn ngữ mã nguồn mở (như Llama 3) ngay tại máy chủ nội bộ. Điều này đảm bảo dữ liệu không bao giờ được dùng để huấn luyện cho các AI công cộng.
Tôi có cần đội ngũ lập trình viên cực giỏi để xây dựng RAG không?
Bạn cần một đội ngũ hiểu về AI Engineering và quản trị dữ liệu. Tuy nhiên, với sự phát triển của các công cụ “No-code” và “Low-code” dành cho AI hiện nay, việc xây dựng một hệ thống RAG cơ bản đã trở nên dễ dàng hơn nhiều. Đối với các hệ thống phức tạp, doanh nghiệp nên tìm đến các đơn vị tư vấn chuyên nghiệp như Midas Agency để tối ưu hóa hiệu suất và bảo mật.